sklearn decision tree
Randomized Decision Tree algorithms As we know that a DT is usually trained by recursively splitting the data but being prone to overfit they have been transformed to random forests by training many trees over various subsamples of the data. Decision trees are an intuitive supervised machine learning algorithm that allows you to classify data with high degrees of accuracy.
 |
| How To Visualize A Decision Tree From A Random Forest In Python Using Scikit Learn Decision Tree Deep Learning Data Science |
Decision Tree is a decision-making tool that uses a flowchart-like tree structure or is a model of decisions and all of their possible results including outcomes input costs and utility.
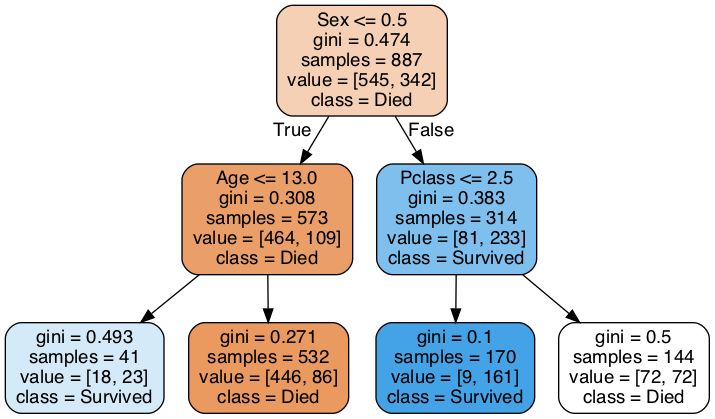
. Decision-tree algorithm falls under the category of supervised learning algorithms. These conditions are decided by an algorithm based on data at hand. It also stores the entire binary tree structure represented as a number of parallel arrays. Scikit-learn uses an optimised version of the CART.
The default value is gini but you can also use entropy as a metric for impurity. Parameters Parameters used by DecisionTreeRegressor are almost same as that were used in DecisionTreeClassifier module. Class sklearntreeDecisionTreeRegressor criterionsquared_error splitterbest max_depthNone min_samples_split2 min_samples_leaf1 min_weight_fraction_leaf00 max_featuresNone random_stateNone max_leaf_nodesNone min_impurity_decrease00 ccp_alpha00 source A decision tree regressor. This parameter determines how the impurity of a split will be measured.
The algorithm uses training data to create rules that can be represented by a tree structure. How many conditions kind of conditions and answers to that conditions are based on data and will be different for each. If None generic names will be used X0 X1. The topmost node in a decision tree is known as the root node.
Scikit-Learn Decision Tree Parameters If you take a look at the parameters the DecisionTreeClassifier can take you might be surprised so lets look at some of them. Sklearn Module The Scikit-learn library provides the module name DecisionTreeRegressor for applying decision trees on regression problems. To reach to the leaf the sample is propagated through nodes starting at the root node. If None the tree is fully generated.
It learns to partition on the basis of the attribute value. Based on these conditions decisions are made to the task at hand. Decision Trees are a class of algorithms that are based on if and else conditions. The intuition behind the decision tree algorithm is simple yet also very powerful.
For each attribute in the dataset the decision tree algorithm forms a node where the most important attribute is placed. The decision classifier has an attribute called tree_ which allows access to low level attributes such as node_count the total number of nodes and max_depth the maximal depth of the tree. In this tutorial youll learn how to create a decision tree classifier using Sklearn and Python. Like any other tree representation it has a root node internal nodes and leaf nodes.
The target values are presented in the tree leaves. Import numpy as np from sklearnmodel_selection import train_test_split from sklearndatasets import load_iris from sklearntree import DecisionTreeClassifier iris load_iris X irisdata y iristarget X_train X_test y_train y_test train_test_splitX y random_state0 estimator DecisionTreeClassifiermax_leaf_nodes3 random_state0 estimatorfitX_train. A decision tree is one of most frequently and widely used supervised machine learning algorithms that can perform both regression and classification tasks. The maximum depth of the representation.
The sklearnensemble module is having following two algorithms based on randomized decision trees. CART Classification and Regression Trees is very similar to C45 but it differs in that it supports numerical target variables regression and does not compute rule sets. Feature_names list of strings defaultNone. Decision_tree decision tree regressor or classifier.
Decision tree is a type of supervised learning algorithm that can be used for both regression and classification problems. CART constructs binary trees using the feature and threshold that yield the largest information gain at each node. Read more in the User Guide. In this tutorial youll learn how the algorithm works how to choose different parameters for your model how to test the models accuracy and tune.
The good thing about the Decision Tree classifier from scikit-learn is that the target variables can be either categorical or numerical. Names of each of the features. Up to 25 cash back A decision tree is a flowchart-like tree structure where an internal node represents feature or attribute the branch represents a decision rule and each leaf node represents the outcome. Level up your programming skills with exercises across 52 languages and insightful discussion with our dedicated team of welcoming mentors.
The decision tree to be plotted. The difference lies in criterion parameter. For clarity purposes we use the individual flower names as the category for our implementation that makes it. It works for both continuous as well as categorical output variables.
A Decision Tree is a supervised algorithm used in machine learning. It is using a binary tree graph each node has two children to assign for each data sample a target value. The i-th element of each array holds information about the node i.
 |
| Building Decision Tree Algorithm In Python With Scikit Learn |
 |
| An Extended Version Of The Scikit Learn Cheat Sheet |
 |
| Building Decision Tree Algorithm In Python With Scikit Learn Decision Tree Algorithm Learning |
 |
| Visualizing Decision Trees With Python Scikit Learn Graphviz Matplotlib |
 |
| An Introduction To Decision Trees With Python And Scikit Learn Decision Tree Supervised Machine Learning Machine Learning Models |

Posting Komentar untuk "sklearn decision tree"